Especificidad y Sensibilidad. Parte 2
- ruthhenquin

- 16 jul 2023
- 4 min de lectura

Criterios de Repetibilidad
Otra característica muy importante en una prueba de tamizaje o diagnóstica es su repetibilidad.
¿Podemos obtener el mismo resultado si repetimos la prueba?
Independientemente de la Sensibilidad, la Especificidad y los valores predictivos de una prueba, si sus resultados no son reproducibles, su valor y utilidad son mínimos.
Las fuentes que producen variaciones en los resultados de una prueba son dos:
Variabilidad Intrasujeto: Los resultados de una prueba en un mismo individuo varían durante el día. No es lo mismo medir la glucemia en ayunas que después de las comidas, ni tomar la tensión arterial en diferentes horas del día.
También las condiciones bajo las que se realiza la prueba (postejercicio, postprandial, en el consultorio, en casa) producen variabilidad de los resultados.
Es por eso que, a la hora de evaluar un resultado, hay que tener en cuenta las condiciones en las que se realizó la prueba, y es por esto mismo que muchos estudios se deben realizar bajo ciertas condiciones para que sus resultados sean comparables.
Variabilidad Interobservador: No todos los examinadores de ciertos estudios llegan al mismo resultado. Esto es particularmente frecuente en los diagnósticos por imágenes. Otros ejemplos son el examen físico de un paciente, o el equipo con el que se hace una determinación de laboratorio; de ahí la importancia de tener patrones de calibración estándar.
Prueba de Kappa
La variabilidad interobservador se evalúa mediante una prueba denominada Kappa o prueba de Concordancia .
Con esta prueba se comparan los resultados reportados por 2 o más observadores y se calcula la probabilidad de que estos observadores hayan concordado sólo por azar.
Lo importante para nosotros es demostrar que los observadores no han concordado por azar, sino porque el método es bueno y repetible, independientemente del observador.
Constituye un error grave contar el número de concordancias entre los observadores y dividirlo por el número total de observaciones, ya que en muchos casos esto puede deberse a las características de la población estudiada.
Veamos un ejemplo. En la tabla se muestra la clasificación en grado de 75 tumores determinadas por 2 patólogos.
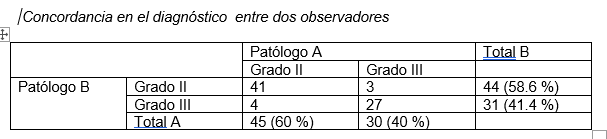
Estos dos patólogos han concordado en 41 tumores clasificándolos con grado II y en 27 clasificándolos como grado III.
Si cometemos el error de sumar las concordancias y dividirlas por el número total de tumores obtendremos:
Concordancia: (41 + 27)/75 x 100 = 90.7 %
Este 90 % es falso, ya que no toma en consideración la posibilidad de concordancia por azar.
Si ahora aplicamos la prueba de Kappa obtendremos un 81 %, que es mucho menor al obtenido anteriormente.
La prueba de Kappa se calcula como:

El cálculo de los porcentajes esperados por azar lo calcula el programa estadístico.
Lo importante es saber que para determinar el grado de concordancia entre observadores, se debe utilizar la prueba de Kappa.
Valores de Kappa por encima del 75 % se consideran buenos, entre 75 % y 40 % intermedios y menores al 40 % malos.
Si el resultado de la nueva prueba es una variable cuantitativa, como por ejemplo visto de creatinina y filtrado glomerular, las dos pruebas se comparan mediante la prueba de Bland & Altman.
Esta prueba se realiza mediante el empleo de un programa estadístico, pero en síntesis lo que busca determinar es si los valores encontrados en la nueva prueba no superan los límites del IC 95 % de la prueba de referencia.
Tanto la prueba de Kappa como el metodo Bland & Altman DEBEN ser utilizados cuando quremos comparar 2 metodos para medir una misma variable. Es un error reportar regresion para decir si dos metodos intercambiables.
Cuando se introduce una nueva prueba de Screening o de Diagnóstico, los estudios realizados para determinar sus características de validez, confiabilidad y repetibilidad deben estar bien diseñados.
Todos los pacientes deben realizarse los dos estudios y la comparación del resultado de la nueva prueba vs. la prueba estándar debe hacerse de forma ciega, para no introducir Sesgos de Información Si se conoce el resultado de la prueba estándar, esto influenciará el resultado de la nueva prueba.
Hay circunstancias en las cuales la prueba de referencia es invasivo o tiene riesgos, y desde el punto de vista ético no sería correcto realizarlo en pacientes sin indicación. En este caso los pacientes con resultado negativo en la nueva prueba son seguidos en el tiempo para evaluar si desarrollan la enfermedad y de esta manera se les evita el riesgo de la prueba estándar.
La nueva prueba debe evaluarse en diferentes poblaciones con todos los estadios de la enfermedad para determinar en qué grupo de pacientes se consigue el mejor costo/beneficio.
Una vez determinadas sus características y costo/beneficio, el estudio debe repetirse en un segundo grupo independiente de pacientes para determinar con mayor confiabilidad si los resultados pueden ser duplicados.
En resumen, lo que se desea con una buena prueba es que, a través de su validez, mida o detecte con la mayor exactitud el evento de interés y con la menor variabilidad posibles.
Todas las características explicadas en este capítulo deben ser tenidas en cuenta a la hora de valorar la utilidad de una nueva prueba de screening o diagnóstica, y a veces la de una prueba que ya está en uso pero que no ha sido ampliamente estudiada desde este punto de vista.


Comentarios